How We Cut Our Deployment Time From Over 30 Minutes to a Few Minutes After Moving to a Monorepo
17/11/2025
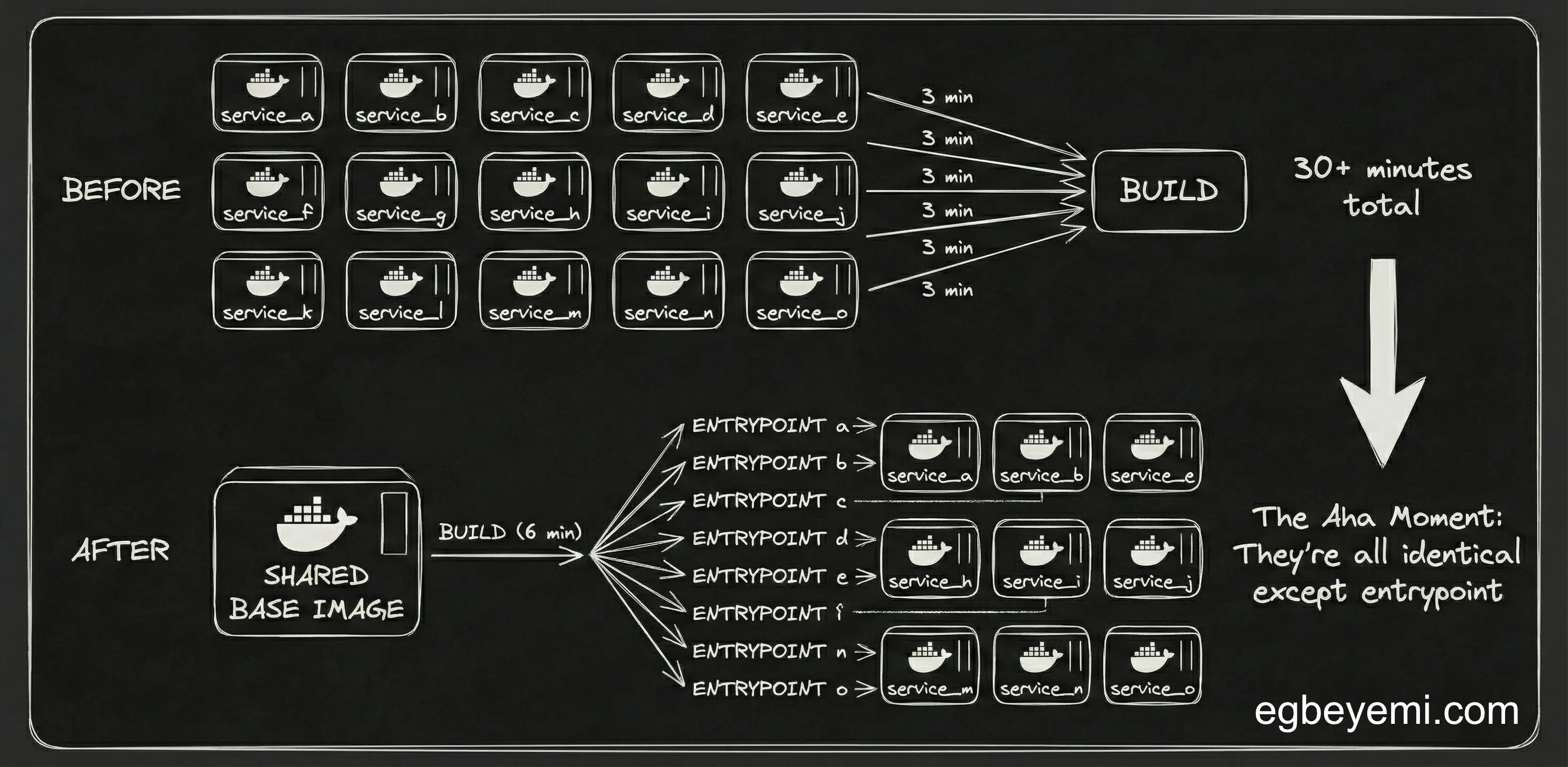
Feels like a lifetime ago in startup years, but we used to run our platform across a collection of separate repositories, one repo per service, plus a ‘utilities’ repo for shared libraries. It worked okay for a while, but as the system grew more sophisticated, the overhead of coordinating changes, and improvements across multiple repos quickly started to wear our small team down.
By that point, we already had about fifteen Python-based services deployed to GCP Cloud Run. The move to a monorepo made development smoother, and the codebase a bit easier to reason about, but it also brought a realisation that we hadn’t made until it was possible to build and deploy all services at the same time: our deployment pipeline was a lot slower and considerably more redundant than it needed to be.
The Problem
After the move to a monorepo, we standardised a CI/CD pipeline that built, and deployed each service separately. We used multi-stage Docker builds with a dedicated build target for each service:
FROM python AS base
COPY stuff app/
FROM base AS service_a
FROM base AS service_b
...Even though the services were functionally independent, the build targets were nearly identical, with the same dependencies, same environment setup, and shared code. The only differentiator was the entrypoint each service used.
Because our CI/CD pipeline built a separate image for each service, we ended up with:
- ~3 minutes to build a single service
- 10–15 services per deployment
- Full rollout time often exceeding 30 minutes This significantly limited our iteration speed, as a small change required waiting half an hour to see it running in staging - especially if it is a change to shared code.
Early Attempts
Our first instinct was to make the pipeline faster without changing the architecture.
Parallel builds
Running 5 parallel builds at once in the GitHub runner brought down the stopwatch time, but at a steep cost. GitHub Actions billing is per-runner, so parallelisation simply multiplied our bill. The GitHub actions quota email was … interesting.
Docker buildx caching
Caching improved warm builds, reducing the build time for the less complex services to a couple of minutes. This was helpful, but it didn’t solve the real issue, which was that we were still rebuilding the same layers again and again for each service.
These attempts made the pipeline feel slightly less painful, but the underlying inefficiency remained.
The Shared Build Stage
The “aha moment” came when we stepped back and looked at the entire Dockerfile structure with caffeine-enhanced clarity. Turned out that most of our services:
- Used the same shared libraries
- Used the same python environment
- Used the same base dependencies
- Executed different parts of the same monorepo codebase The only real difference was the runtime entrypoint
In other words: We were rebuilding fifteen almost identical images when we actually needed just one.
This was when it became clear that the real optimisation was not about tweaking the pipeline, it was about eliminating redundant work entirely.
The Solution
We refactored the Docker setup so that:
- The shared python environment
- Base dependencies
- Common runtime utilities
- The monorepo codebase
…were all baked into a single shared image.
Hence, instead of building one image per service, we built one image for the whole platform, pushed it once, and used Cloud Run’s ability to override entrypoints to tell each service what to run.
This transformed the deployment model:
- Build once
- Push once
- Deploy the same image to all services
- Change only the entrypoint per service.
gcloud run deploy ... service_a --commad "do something --cool"We also decoupled the build step from the deployment step, which meant that we did not always need to re-deploy all services when changes happen
For the few services with unique needs, we created derivative images that extended the base image instead of rebuilding from scratch.
The Outcome
After refactoring the docker setup and separating the image build from the deployment stage, or pipeline became both faster, and easier to reason about:
- The shared base image build now takes on the order of a couple of minutes with cache.
- Deploying all services took ~3 minutes or ~1 minute if it’s a single service.
- End-to-end a full build-and-deploy for the platform went from tens of minutes to roughly six minutes.
The qualitative difference was just as important as the numbers. Instead of treating “build + deploy everything” as one opaque pipeline, we now:
- Build the container image once when there is any code change
- Reuse it for fast, repeatable deployments across services
The net effect was much tighter feedback loop. Getting a change into staging went from “go make a gourmet sandwich” to “go get some instant coffee”.
Want to talk about Software/AI Infrastructure?